A side quest to explore old code.
Something I’ve been wanting to do ever since acquiring my Apple IIc Plus at KansasFest is to dig into the ROM. Before the days of commodity Intel hardware, computers were very different things. Modern computers have this vestigial ROM-like thing called a BIOS, which is a minimal bit of goo used to get the mass storage device going when you turn the machine on. RAM is cheap, and the drives are fast, so it makes perfect sense to load as much of the operating system as possible into volatile memory. This gives you maximum flexibility- the software can be updated at any time, and the same set of hardware can run any combination of software and operating system.
In the 1970s and ’80s, however, the value propositions were all very different. Mass storage was only in the form of tapes (glacially slow) or floppy disks (merely very slow). RAM, meanwhile, was monumentally expensive. It’s hard to overstate the impact that the cost of RAM had on all electronics for a couple of generations. Nowadays, companies largely hold back RAM as a value-add to get you to spend more money. In the old days, however, the cost of RAM was the driving factor in nearly every architectural decision an engineer made in a computing system.
What is a 1980s computer designer to do? RAM costs a fortune, you need to hit a consumer-friendly price point, and you need an experience that doesn’t suck while trying to load an operating system from a 5¼” floppy disk or (gasp) cassette tape. The solution, as you probably know, was ROM. Mask ROMs, while expensive to develop, are relatively cheap to make in quantity. They are also basically (pardon the pun) as fast as RAM. As a result of these economic maths, computers of the period put significant portions of what we would now call “software” into ROM. Disk operating systems, programming languages, graphics libraries, windowing systems, hardware drivers, the list goes on. There’s almost no limit to what early computer designers would try to jam into ROM. It’s all in the name of saving precious RAM, and alleviating the need to load this stuff from slow mass storage every time you power on. It’s also worth noting that these early home computers were rebooted a lot. Vastly more than even the most unstable Windows machine. You generally rebooted every time you switched applications, and that was just the intentional reboots. If you were a developer, you might reboot as often as every couple of minutes (especially if developing interrupt code, or other sensitive low-level things). What we would now call a “blue screen of death” wasn’t just a subset of bugs that could occur. Virtually anything that went wrong in software brought the whole machine down. The point is, boot times mattered a lot. To that end, ROM was a huge win here. Later machines of this early generation, such as the Amiga, Apple IIgs, and original Mac, took this to extremes with positively huge ROMs. They were hundreds of kilobytes, and sometimes over a megabyte, of code. GUI systems, rendering libraries, font engines- all kinds of stuff was hiding in the silicon on the motherboard.
You can see the fruits of these efforts by simply turning on an old machine. It boots virtually instantly into a prompt that lets you write code, examine memory, debug, talk to peripherals, and all sorts of other things.
What’s the point of this history lesson? Well, despite edumicating the whipper snappers in the audience, the point is that there’s a lot of interesting old code locked up in the ROMs of these machines. I want to poke around in it. Who wouldn’t? It also helps to understand the obvious downside of this ROM-heavy approach to computing system design. This code can’t change. It’s set at manufacture time, and users have to live with it, bugs and all, for years or even decades. This became such a problem that some machines would patch the ROM by loading corrected code into RAM at startup, and directing applications to use that code instead. This, of course, defeats the whole purpose of the ROM while also slowing down boot times. The Amiga and Apple IIgs were particularly notorious for this. The other solution is to release new ROM revisions (something the IIgs also did a lot of), but this is slow and drives customers (and developers) crazy.
I realize that was a lot of words, and nobody likes reading. So let’s get to the point of this hack. I want to dig into the ROM of my Apple IIc Plus. The complete ROM contents of pretty much every Apple II model can be found online without much effort. In fact, the early machines came with complete ROM listings in their instruction manuals. Furthermore, early Apple II machines have a built in ROM Monitor that allows you to view and disassemble the contents of ROM. There are many convenient, easy ways to examine and explore this old ROM code.
I’m going to do none of that.
I want to do it the hard way, and dump the contents of the chip itself. Why? Because it’s fun, and also because the IIc Plus ROM is a bit more obscure and less well documented than most other Apple II models. This machine came at the very end of the run, didn’t sell well, and doesn’t get a lot of attention from hackers.
In a recent post, I put together a breakout board for the ATMega32U4. As you might have guessed, I had an ulterior motive for doing this. I intend to expand that into a dumper for Apple II ROM chips. It will also be expanded to an EEPROM writer, so I can modify the code. A ROM tool of this sort is nothing new on Blondihacks. I did this with an ATTiny microcontroller way back in the early days of Veronica. The old girl has an onboard EEPROM writer which is very useful for developing ROM code in-situ. However, that thing is very specialized to Veronica’s needs, and in fact was a giant pain in the ass to make. The ATTiny, while a favorite chip of mine, has very little general purpose IO. That means I needed to use a lot of shift registers to access all the address and data lines of an EEPROM, and that in turn made the code a hassle to get right. I also have somewhat grander visions for this new ROM tool. While Veronica’s EEPROM writer can only burn code that is held by the ATTiny itself (uploaded via AVR programmer), I wanted this new tool to stream the code over USB.
The basic design is to have a zero-insertion-force (ZIF) socket for the ROM chip, a USB port to connect to a computer, and a microcontroller to manage everything in between. I wanted a simple, low-chip-count design that would be easy for people to use (or potentially buy from me, if anyone wants one).
In an effort to simplify this task, I wanted a single chip that had enough I/O to wrangle a 32kbit EEPROM all by itself, and could speak USB. This led me to the ATMega32U4, and subsequent breakout board.

The software for this project is going to be relatively complex, but the hardware is quite simple. As I’ve mentioned previously, I’ve recently become quite enamored with KiCad. It will be pressed into service once again for this project. All the hardware and software files involved with the project are available on GitHub.
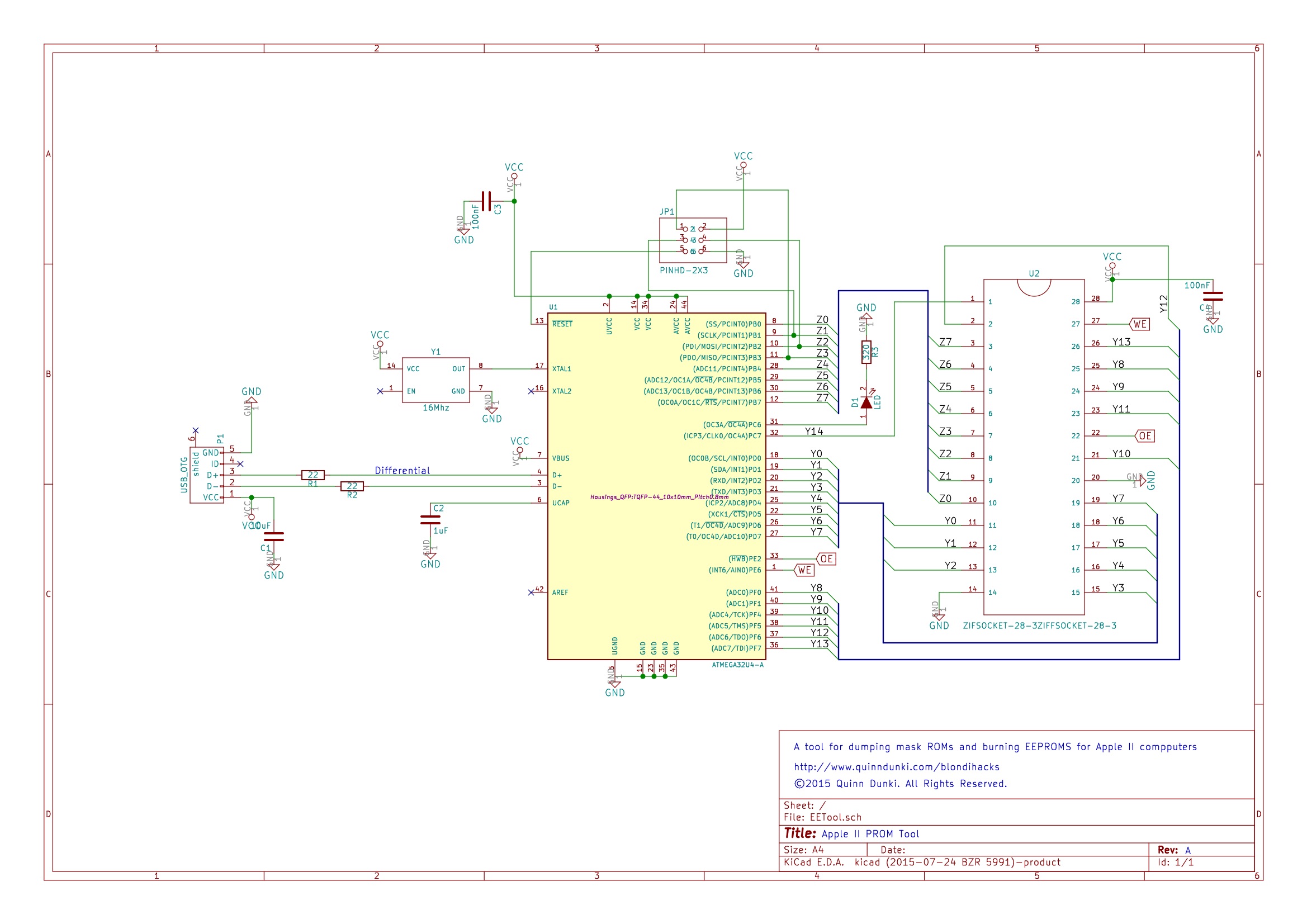
Next up is the PCB layout. I always enjoy this part of the process. It’s very satisfying. I knew there would be layout challenges here, because the microcontroller is a four-sided package, and the address lines on a 32kbit ROM are quite jumbled. A two-layer board would neatly solve all these problems, so I went for it.

I decided to try one more new thing on this project. Since the very earliest days of Blondihacks, I’ve been a big proponent of etching circuit boards at home. It’s incredibly inexpensive, the turnaround is a matter of an hour or so, and the process is fun to do. However, there are some types of boards for which home etching is not a great solution. A good example of such a project is one involving 0.8mm pitch TQFP-44 surface-mount packages, multiple layers, lots of vias, and very fine traces packed closely together. Guess what? That’s what we need this time. Luckily, KiCad integrates very well with OSH Park, so I decided to give them a go. I chose them because they are well regarded, fairly inexpensive, relatively local, and their boards are purple. If I said that last part was not a factor, I would be lying. The boards they produce are BOOOOOOTIFUL.
The real downside to having boards made (aside from cost) is the time involved. Since they need to panelize your PCB with others to be able to make such small quantities for each person, it can take a while. In my case, it was about two weeks, which is actually better than I expected. These small-run board houses are also a good choice for SMT projects, because you want to keep your PCB size down (they charge by area), and they can do multiple layers with small traces. The other risk is that you’ll make a mistake on your board. You’ll want to be very careful with your layout before pushing that manufacturing button, because a mistake will cost quite a bit of time and money. If you have access to circuit simulators, that’s a great way to mitigate this risk. In my case, this design is so simple that the risk is low. It’s a good candidate to try out this process. As you’ll see, it was close to a raging success!

I described these boards as “almost” a raging success, because I did make one small rookie mistake. I trusted the footprint I had for the ZIF socket, and neglected to measure the actual parts I have here (which were acquired as surplus during a road trip to the TRW swap meet). The decoupling capacitor that I included for the ROM chip landed completely underneath the ZIF socket. It probably would be fine to leave the cap off (this is a small, low-speed board), but I simply mounted this cap on the back instead. The other thing I would change in this design is to make it a lot smaller. It could be made much more compact with better layout and component choices. I wasn’t thinking about the per-square-inch costs though, and I paid the price at manufacture-time.
The next step was to mount sufficient components to get the microcontroller up and running. I don’t need to build the whole thing yet, because the bulk of this project will be software. I need just enough to talk to the ATMega. Some support passives are needed, the clock, the programming header, an LED for debugging, and the USB-related parts. Um… that turns out to be pretty much everything.


One other thing to note on this board…

With the hard bits out of the way, it’s time for the soft bits. Step one is to talk to the microcontroller over USB. This would be a thorny task, but luckily the amazing open-source project called LUFA has solved this problem for us. Really, I can’t say enough good things about this project, and the work Dean Camera has put into it. Go there now and donate to his project. Whether you want to make a keyboard, a game controller, a sensor device, a communications system, a mass-storage device, or something totally custom like this, LUFA has you covered. The samples he provides work great out of the box, although I do recommend reading the documentation. You want to make sure things are set up right for your application to avoid mysterious issues.
One other thing I recommend is, once you get LUFA up and running the way you need for the project at hand, strip it down as much as you can. Remove all unused portions of the source code and build pipeline. Otherwise your iteration times to download code to the microcontroller can get quite long. LUFA is very powerful, but there’s also rather a lot of code in it.
Next, it’s time to set up some communication. I opted to do this with a virtual serial port over USB. This is simple to write, gives me maximum flexibility in my protocol, and will work with any host platform. I happen to be on OS X, but all the code here is platform agnostic.
On the microcontroller side, the setup is simple. We initialize LUFA, then enter a tight loop to watch for data on the virtual serial port. For testing, we echo back anything we receive.
Once you have the LUFA USB client code running on the microcontroller, you should see the device when it’s plugged in. On unixlikes, you’ll see a /dev/tty device appear with a name like “tty.usbmodemXXXX”. On Windows, well, I dunno- stuff happens, I guess. Probably a cartoon paperclip is involved, and a lot of installing stuff and rebooting.
From here, I was able to run some test code on the microcontroller that would let me know the host is being seen and the USB is functioning normally. This was all done via the perennial debugging LED.

A useful tool for testing at this point is a golden-oldie unix tool called screen. It’s technically a VT-100 based virtual terminal environment manager, but it does a very nice job of listening to a serial port and telling us what’s happening on it. For example, configuring the microcontroller to spam text over serial, then opening ‘screen’ on that TTY device gives us this:
Now we need data going the other way. On the computer side, I figured a simple command-line tool to talk to this thing would be the way to go, so I dusted off my verrrry rusty Python skills. Here again I’m using an excellent open source library. pySerial is a platform-agnostic Python library that does a beautiful job of handling the heavy lifting of serial communications for you. On Mac and Linux, it interacts with TTY devices. On Windows, it interacts with COM ports. The documentation is also solid, and all the examples Just Worked™.
I set up the microcontroller side to respond to some basic command codes.
Next, I wrote the Python side of things.
Note that this code is all a snapshot in time as of this writing. For the proper latest (and working) versions of everything, be sure and go to GitHub.
With that all hooked up, I fitted the ZIF socket, and got to work testing things.

Now with ROM hooked up and the code all written, time to test for realsies! I connected everything, fired up the tool, and requested a dump of the ROM.
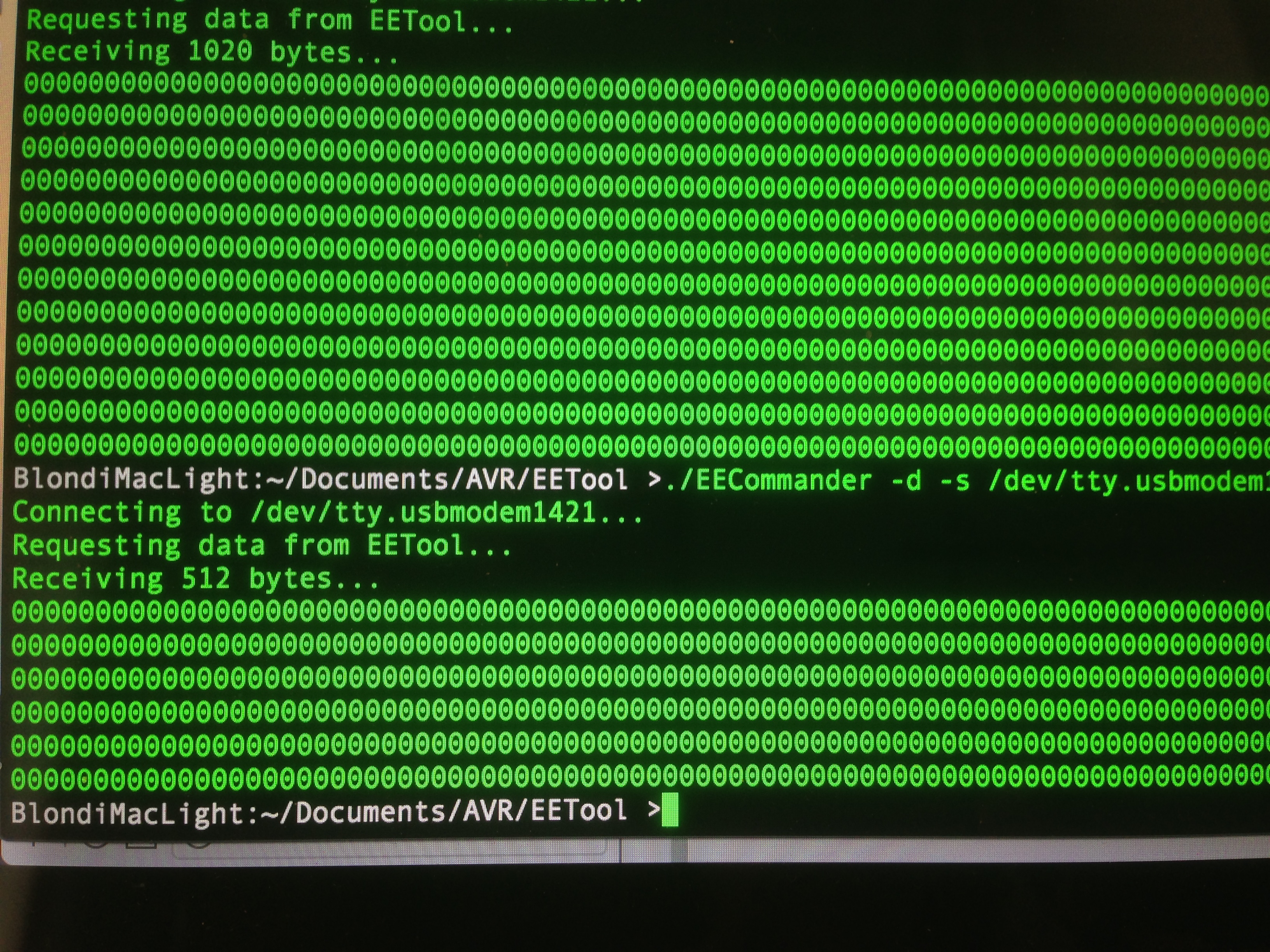
The next step in debugging anything is to eliminate variables. I know my serial communication is good from previous tests, so my interface to the ROM must be wrong. It could be either be problems with how the microcontroller is reading the ROM, or how it is packaging the data to send over serial. An easy way to isolate those cases is to hard-code a value on the data lines. Let’s have the microcontroller always report back a hard-coded value as though it had been read from the ROM.
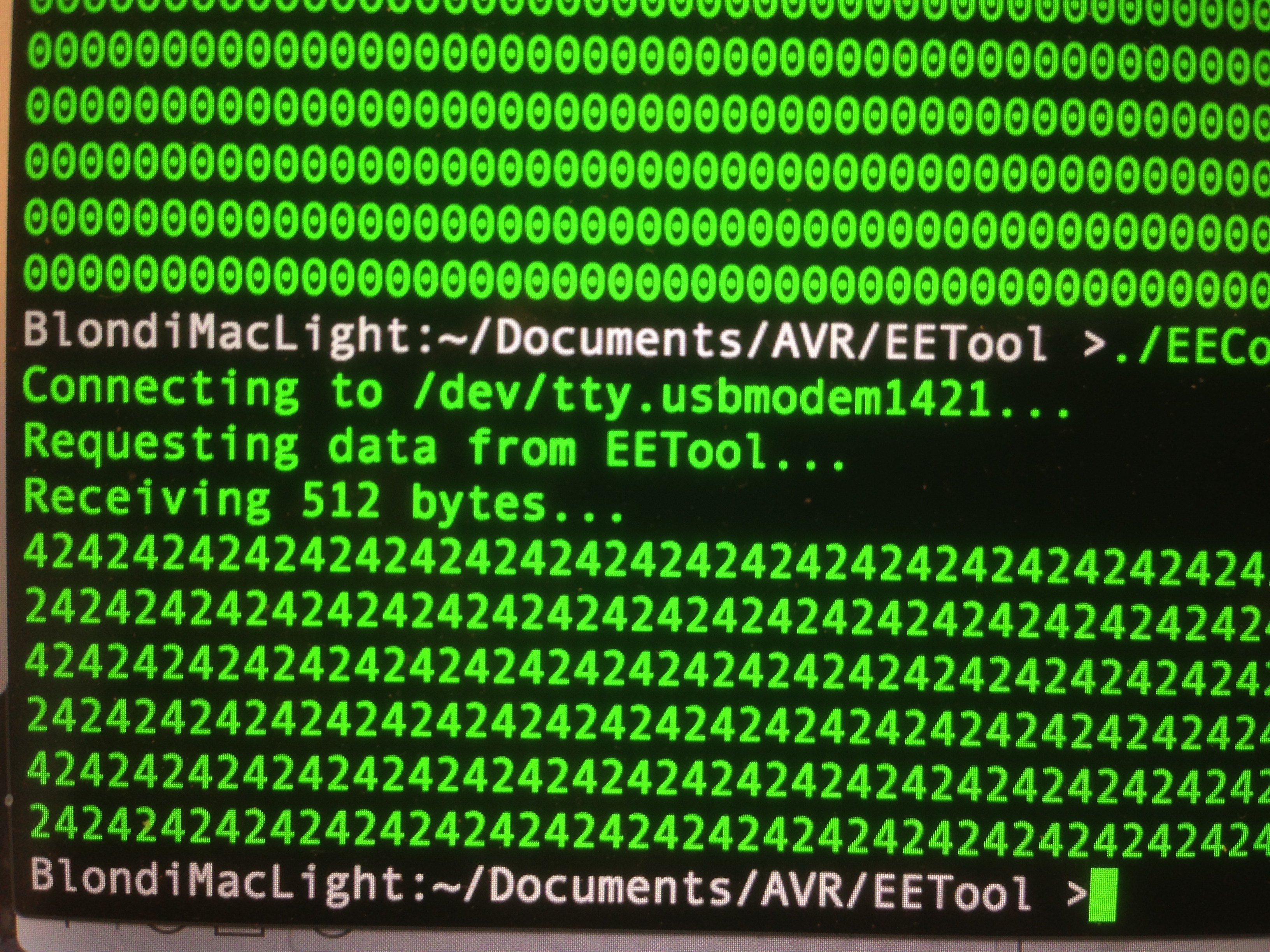
We now know the microcontroller thinks the data coming out of the ROM is all zeroes. This could be because address lines are not set right, data lines are not hooked up right, or possibly control signals are not behaving properly. How can we distinguish between all these possibilities? Time for the logic probe! Since we’re dealing with coarse data and low speeds here, we don’t need any fancy digital logic analyzer or anything. If the Chip Select is set right, and the address lines are counting up, then the data lines will be correct. The logic probe will tell us which of those conditions is not being met.

Some probing revealed the address lines were not all counting up properly. This is easily perceived (even at 16MHz) as a decreasing-pitch tone as you probe upwards on the address bus. A little debugging later (I hadn’t set some pin states correctly in my ATMega code), and we get some lovely sounds.
That’s 32kbits exiting one of our data lines at 16MHz. Music to my ears!
With that working, let’s get back to testing a ROM that we know the contents of (so that we know if the system is working).
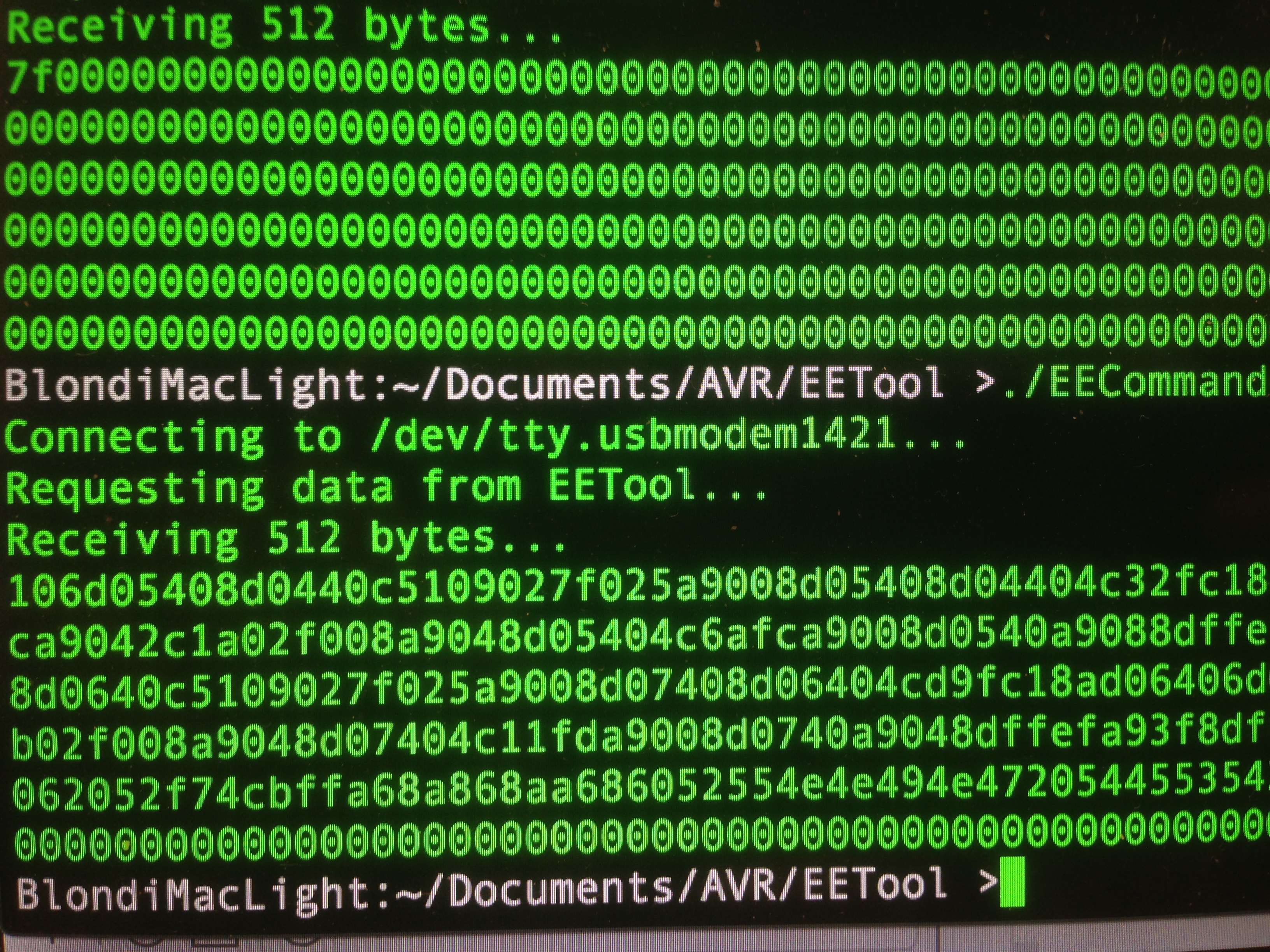
I did have to iron out a few timing issues. The virtual serial port is fast, but the microcontroller and Python script are much faster, so some artificial delays are needed at a couple of key spots. Without them, bytes will be missed, or phantom random ones would creep in. We can’t have that- we need precision for this operation!
All that was left to do is wrap this basic code in a structure that reads one 512 byte block at a time, and sends these blocks over the wire to the host. The host writes these blocks to a file, and in this way the entire 32kbit ROM is dumped. I chose 512 bytes for the block size because that was the largest that LUFA’s virtual serial implementation seemed comfortable with. Much bigger, and bytes started disappearing. I suspect there’s an internal 1k buffer somewhere in the system that is the ultimate limit on this. Of course, much bigger than that, and we’d start to run afoul of RAM limits on the ATMega32U4 as well.
We now have some tools to really start digging into the Apple IIc Plus’ ROM code. Stay tuned for what we find!
So, is the ROM you dumped identical to any of the IIc+ ROMs one can find online? Or would disclosing that be a spoiler? 😉
In the spirit of this hack, I haven’t even looked for this particular ROM image online (yet). I want to do it myself, because it’s a fun excuse to do a lot of new things.
One thing you might want to consider, to make this process more robust is to include some kind of start/end marker on the blocks (something not a hex digit, like a ‘Y’ and a ‘Z’) and to include a simple checksum (just add up all the bytes modulo 255 or something). These small enhancements make it MUCH simpler to know that you’re getting exactly what you think you are. The header/footer would probably be trivial to add, though the checksum might take more work than it’s worth.
Those are great ideas! A checksum sounds like it would be worth it, honestly. I have CRC32 code lying around that I can drop in pretty easily. Thanks for that suggestion!
You are welcome. I’ve done quite a bit with serial protocols in recent years, so it’s all still fresh in my mind.
You could even go as far as letting the microcontroller generating the output in one of the Hex formats that are commonly used by EPROM burners….
And welcome to the PurplePCB club, Quinn! 🙂
===Jac
I’ve been thinking about a related project, and the idea of running a kermit server on the ATmega was the best way I could think of to solve the block checking, flow control, file transfer stuff, etc. The clients are already around, and it would make it platform agnostic in ways most projects can only dream of.
-JRS
This reminds me of an itch I’ve wanted to scratch for some time. I must have several hundred (may be over a thousand) old UV eproms in the junk box. I’ve got everything from 2708’s up to those multi-megabit 40pin word wide types. Most were salvaged from the dumpster at the many places I’ve worked over the years. I’ve also got most of the manuals for these parts in the original data books from Intel, AMD, Hitachi, etc. I even built my own eprom eraser (just germicidal lamp in an old foot long lamp fixture stuffed into a home bent mini box.) I’ve been thinking of building an eprom burner using an Arduino Mega and some of Steve Ciarcia’s old schematics from Byte and CCink. Guess I’ll be borrowing some ideas from your software as well.
Damn! nearly tripped over my jaw (that just hit the floor). Every time I read something new on your blog, I feel just that little bit more inadequate. 😛
I noticed you are using an ATMEL 28C256 EPPROM. Be aware that a couple of vintage hackers have discovered that the ATMEL 28C256 EEPROMs sometimes don’t play well in 6502 systems, making a mess of the address bus. I know someone that played with timing of CS to get around this and another person that gave up trying to make the combination work, so it may or may not be an issue for you. My experience with XICOR EEPROMS has been a little better.
Now there’s a name I know. Thanks for the suggestion. I didn’t have any trouble with the Atmel EEPROMs on Veronica’s 6502 architecture, but I did have trouble getting non-counterfeit ones (even from reputable suppliers). I’ll try these since I have them on hand, but will switch to the ones you suggest if I have trouble.
OT, but just in case you missed this, here’s a little extreme 8-bit/breakout board love from Brad over at LucidScience.com: http://forum.6502.org/viewtopic.php?f=4&t=3329
Wow!
If you’re looking for an open source disassembler, there is a great reverse engineering framework: http://www.radare.org (just in case you didn’t know it already).
Thanks for your great projects, I’m looking forward to your next post!
You’ve mentioned KiCad a few times now. I’ve watched a few youtube vids and played with it some; so far I’m really liking it. I was just re-reading your PCB etching guide, as I’m planning to take the plunge soon, and I noted that you had a number of recommendations for the layout work in Eaglecad to help get the best results when etching. Have you considered (or would you?) an updated guide? Or at least a KiCad guide to go with the original etching post?
Good idea- I may try that. Honestly, I’ve found KiCad’s default settings for pretty much everything to work really well for home etching. The learning curve is much shallower than Eagle, and settings are less buried and obscure.
Thumbs-up on KiCad. I’ve been using it for over a year now, and it’s been great. It was really rough before there were MacOS auto builds and an annoying crashing bug in the push and shove router, but it is rock solid now. I’m working on a video walkthrough of doing a simple FPGA dev board layout to get more practice for an FPGA based project I’m working on.
I imagine that you will be writing your own disassembler. 😀
Are you going to dump all three ROMs that are in a IIc+, or just the system ROM? There probably isn’t anything of great significance in the keyboard ROM or the video ROM. One contains keymaps, the other contains character images.
Just the Monitor ROM (aka “main ROM” or “system ROM”). The other chips are the same in all models from Enhanced //e onwards, so nothing much to learn there. The IIc+ monitor ROM, as far as I know, is relatively uncharted territory.